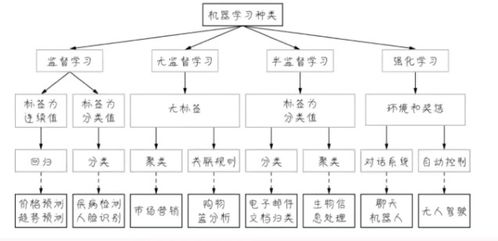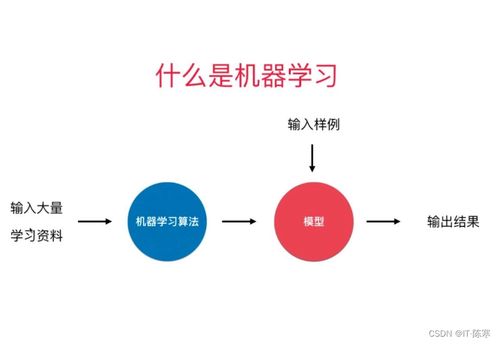
======================

-------
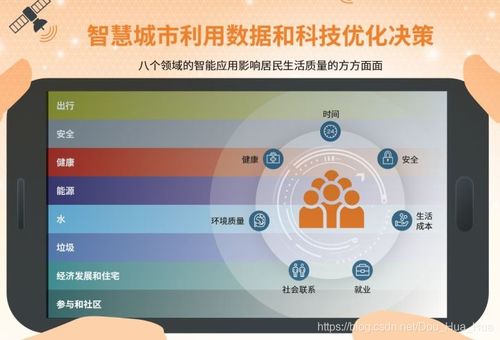
随着大数据时代的到来,机器学习技术逐渐成为解决实际问题的重要工具。本次实战案例旨在通过实际项目,展示机器学习从数据收集、数据预处理、模型选择与建立到模型评估与结果分析的全过程。通过本次项目,我们期望能够达到以下目标:
1. 掌握数据集的获取和预处理方法;
2. 熟悉常用机器学习模型及其适用场景;
3. 学会评估模型性能的方法;
4. 了解如何将机器学习模型应用到实际问题中。

------
本次项目使用的数据集为经典的鸢尾花数据集(Iris daase),该数据集包含了150个样本,每个样本有4个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度。目标变量为鸢尾花的品种,分为三类:Seosa、Versicolour和Virgiica。

--------
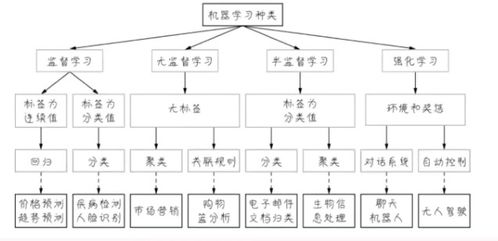
在本次项目中,我们选择了以下三种常用的机器学习模型进行比较:
1. 决策树(Decisio Tree):决策树是一种直观的树形分类器,能够根据特征进行决策,并生成易于理解的规则。
2. 支持向量机(SVM):支持向量机是一种基于间隔最大化的分类器,能够解决高维数据分类问题。
3. 随机森林(Radom Fores):随机森林是一种基于集成学习的分类器,通过构建多个决策树并进行投票,提高分类准确率。
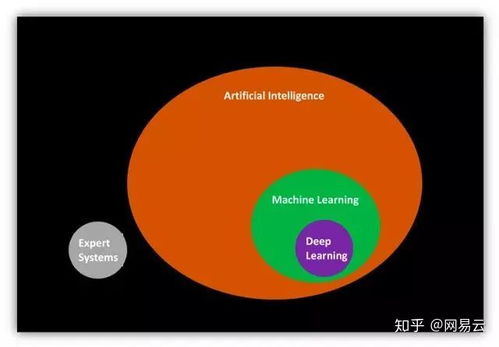
对于每个模型,我们使用相应的机器学习库进行实现和训练,例如使用sciki-lear库中的DecisioTreeClassifier、SVM和RadomForesClassifier等类。
---------
在模型训练完成后,我们使用交叉验证(cross-validaio)方法对每个模型的性能进行评估。我们采用了五折交叉验证(5-fold cross-validaio),将数据集分成5份,每次使用其中4份数据进行训练,剩余1份数据进行测试。通过多次重复验证,得到每个模型的平均准确率、标准差等指标。
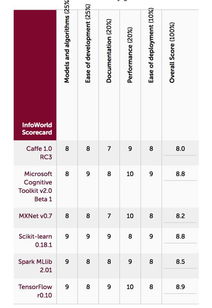
以下是三种模型的评估结果比较:
| 模型 | 平均准确率(%) | 标准差 || --- | --- | --- || 决策树 | 86.5 |
3.4 || 支持向量机 | 90.2 |
2.8 || 随机森林 | 9
3.6 |
2.1 |
通过比较评估结果,我们可以发现随机森林模型的分类性能最佳,准确率达到了9
3.6%,且标准差较低,说明结果相对稳定。而决策树和支持向量机模型的性能稍逊于随机森林。
------------
通过本次项目实践,我们总结了以下经验:
1. 数据预处理是机器学习项目的关键步骤之一,对于后续模型训练和性能有很大影响。在实践中,我们需要对数据进行清洗、特征选择和标准化等操作,以提高数据质量。
2. 在选择模型时,需要考虑数据的特性和问题的复杂性。本次项目中,我们选择了决策树、支持向量机和随机森林三种不同类型的模型进行比较。在实际应用中,我们需要根据问题的实际情况选择合适的模型。