===================
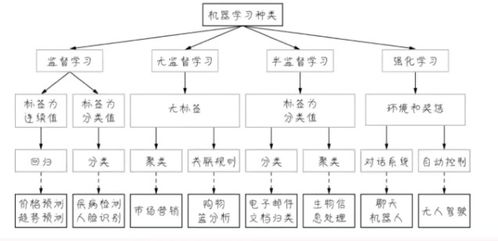
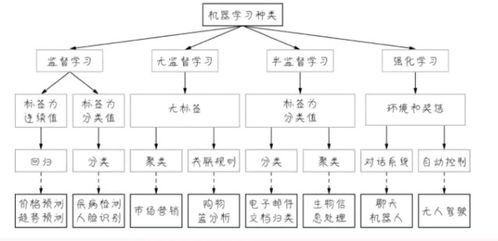
1. 监督式学习--------
### 定义
监督式学习是一种机器学习方法,它依赖于带标签的训练数据。在此类学习中,我们提供一组输入数据,以及与每个输入数据相关联的正确输出或标签。监督式学习的目标是找出输入和输出之间的关系,以便在给定新的输入数据时能够预测其正确的输出。
### 例子
以分类问题为例,我们有一组带有标签的图片(猫、狗),我们的目标是训练模型,使其能够识别新的图片并正确地分类为猫或狗。
### 方法
监督式学习的主要方法包括回归分析、逻辑回归、支持向量机(SVM)、决策树等。这些方法都试图从已知数据中找出模式,并以此来预测未知数据的结果。
2. 无监督学习--------
### 定义
无监督学习是一种机器学习方法,它不依赖于带标签的训练数据。在此类学习中,我们提供一组输入数据,但并没有与之关联的正确输出或标签。无监督学习的目标是找出数据中的模式、聚类或关系。
### 例子
以聚类为例,我们有一组用户的购买行为数据,目标是找出具有相似购买习惯的用户群体。这里并没有明确的“正确答案”,而是需要从数据中自行发现结构。
### 方法
无监督学习的主要方法包括聚类分析(例如K-meas、层次聚类)、降维(例如主成分分析PCA)和关联规则学习等。这些方法都试图从数据中找出隐藏的模式或关系。
3. 比较----
### 区别
监督式学习和无监督学习的主要区别在于它们所依赖的数据类型和目标。监督式学习依赖于带标签的数据,目标是预测未知的结果;而无监督学习不依赖于带标签的数据,目标是发现数据中的模式或关系。
### 应用场景
监督式学习在很多场景中都有广泛的应用,例如语音识别、图像识别、自然语言处理等。而无监督学习则常常应用于市场细分、行为分析、网络流量分析等场景。
4. 结论:优劣比较和选择-------------
监督式学习具有明确的目标和评估标准,通常在预测新数据方面具有较好的性能。它需要大量的带标签数据,这对于某些应用可能是一项挑战。无监督学习则不需要带标签的数据,可以发现数据中的隐藏模式或关系,但可能缺乏明确的评估指标,对于新数据的预测性能也可能较差。
选择哪种学习方法取决于具体的应用场景和目标。如果目标是对新数据进行预测,且拥有大量的带标签数据,那么监督式学习可能是更好的选择。如果目标是理解数据的内在结构和关系,且没有大量的带标签数据,那么无监督学习可能更合适。在实际应用中,往往需要结合具体的需求和限制来选择合适的学习方法。