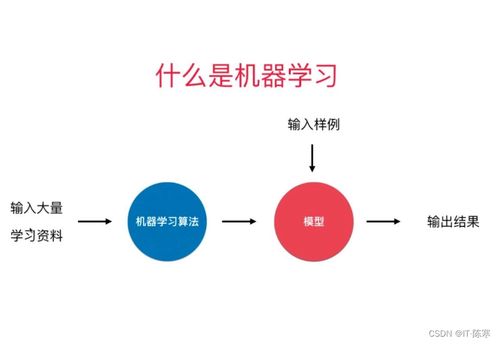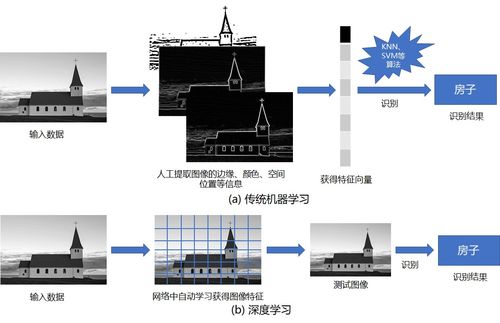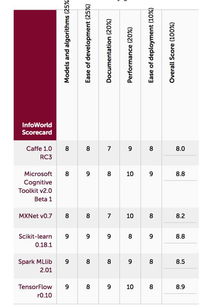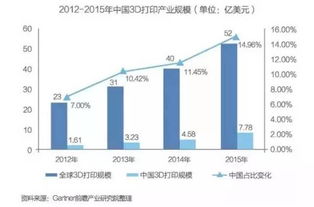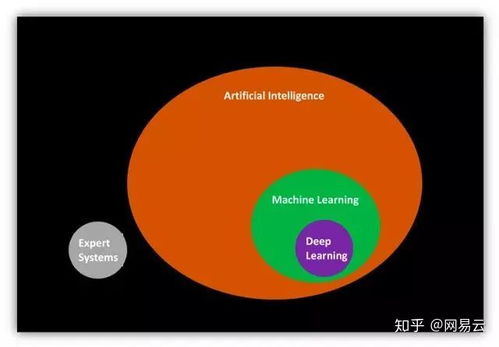
1. 引言
随着信息技术的快速发展,网络安全问题日益突出。传统的安全防护手段往往基于预先设定的规则和模式,难以应对复杂多变的网络攻击。近年来,机器学习技术在许多领域取得了显著的成果,也在网络安全领域发挥了重要的作用。
2. 机器学习在网络安全中的重要性
机器学习技术可以通过分析大量的网络流量数据,自动识别和预测网络中的异常行为,从而预防和检测网络攻击。机器学习还可以提高网络防御的自动化程度,减少人工干预的需要,提高防御效率。
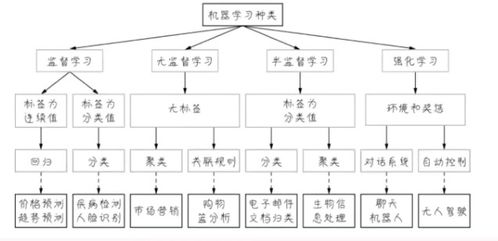
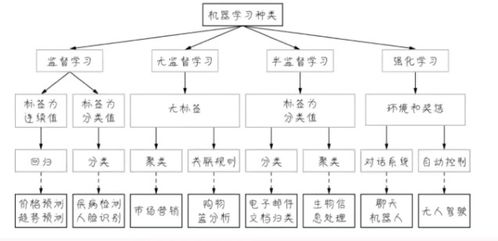
3. 机器学习的种类和应用
3.1 监督学习
监督学习是一种通过已知输入和输出来训练模型的方法。在网络安全中,监督学习可以用于识别恶意软件、网络钓鱼等行为。例如,通过训练模型来识别包含恶意代码的软件,或者识别包含钓鱼网站的URL。
3.2 无监督学习
无监督学习是一种在没有标签数据的情况下训练模型的方法。在网络安全中,无监督学习可以用于聚类分析、异常检测等。例如,通过聚类分析来识别出具有相似特征的网络攻击行为,或者通过异常检测来识别出与正常行为不同的异常行为。
3.3 强化学习
强化学习是一种通过试错来训练模型的方法。在网络安全中,强化学习可以用于自动生成防御策略、优化系统配置等。例如,通过强化学习来自动生成能够抵御网络攻击的防火墙规则,或者优化系统的安全配置。
4. 机器学习在网络安全中的具体应用
4.1 恶意软件检测
机器学习可以通过分析软件的代码、行为等特征,自动识别出恶意软件。机器学习可以通过监督学习、无监督学习等方法来训练模型,实现自动化检测。
4.2 钓鱼网站识别
钓鱼网站是一种常见的网络攻击方式。机器学习可以通过分析网站的文本、链接、页面结构等特征,自动识别出钓鱼网站。机器学习可以通过监督学习、无监督学习等方法来训练模型,实现自动化检测。
4.3 零日漏洞利用检测
零日漏洞是一种危害性极大的攻击方式。机器学习可以通过分析网络流量数据,自动识别出利用零日漏洞的网络攻击行为。机器学习可以通过监督学习、无监督学习等方法来训练模型,实现自动化检测。
5. 面临的挑战和解决方案
5.1 数据稀缺和质量问题
在机器学习中,数据的质量和数量是影响模型性能的关键因素。在网络安全领域,高质量的数据往往稀缺且难以获取。为了解决这个问题,可以采用数据增强、迁移学习等技术来提高数据的质量和数量。同时,还可以通过合作共享来提高数据的质量和数量。
5.2 模型泛化和鲁棒性问题
模型的泛化和鲁棒性是机器学习的两个重要指标。在网络安全领域,模型的泛化能力往往受到数据分布的影响,而模型的鲁棒性往往受到攻击者对抗的影响。为了解决这个问题,可以采用集成学习、迁移学习等技术来提高模型的泛化能力,采用防御对抗等技术来提高模型的鲁棒性。
5.3 解释性和透明度问题
机器学习的解释性和透明度是影响其可信度和推广应用的关键因素。在网络安全领域,模型的解释性和透明度往往受到复杂网络环境和未知攻击的影响。为了解决这个问题,可以采用可解释性机器学习等技术来提高模型的解释性和透明度。同时,还可以通过公开模型和代码来提高模型的透明度。