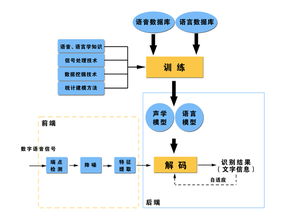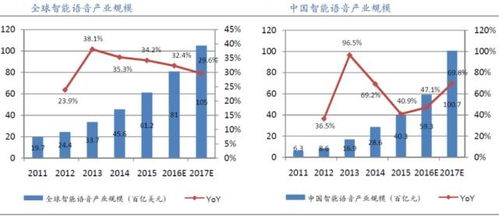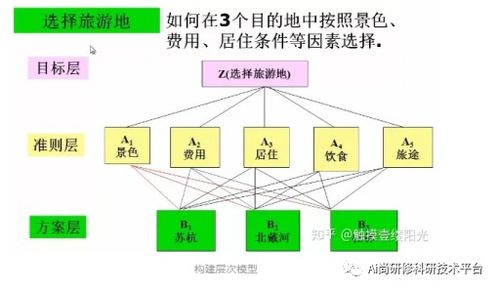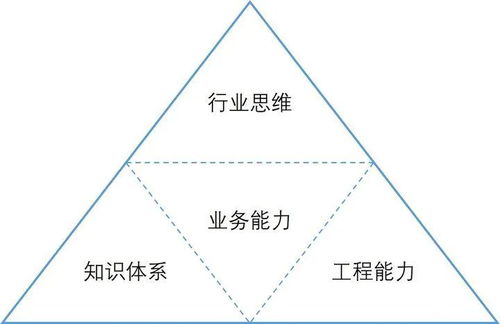

1.文本分类
C最广泛的应用之一是文本分类任务,例如情感分析、垃圾邮件识别等。在这些任务中,C可以通过卷积运算对文本进行特征提取,从而实现对文本的分类。
2.命名实体识别
命名实体识别(ER)是自然语言处理中的一个重要任务,它可以识别文本中的实体,例如人名、地名、组织机构名等。C可以通过对文本进行卷积运算,提取出文本中的特征,从而实现对实体的识别。
3.语言模型
语言模型是一种基于深度学习的自然语言处理技术,它可以预测给定上下文中下一个单词的概率分布。C也可以被用于构建语言模型,例如循环神经网络(R)和长短时记忆网络(LSTM)等。

1.高效性
C是一种高效的特征提取方法,它可以通过卷积运算对文本进行特征提取,从而减少了计算量和时间复杂度。
2.适用性
C可以适用于各种自然语言处理任务,例如文本分类、命名实体识别、语言模型等。同时,C还可以与其他深度学习算法结合使用,例如R和LSTM等。

1.参数设置不当容易过拟合或欠拟合。需要对超参数进行调整以获得更好的效果。同时对语料库的质量和数量有较高要求,当语料库不足时,模型效果可能会不佳。
2.无法处理变长输入。对于不同长度的文本,需要进行长度剪切或者paddig等预处理方式才能输入模型,增加额外计算量。对于某些需要处理特定长度的任务(如LP中的序列到序列任务),C可能不适用。同时受卷积核大小的限制,可能会出现对细节信息的丢失或对全局信息的把握不足的情况。
3.模型可解释性较差。由于卷积神经网络存在较多的非线性变换和池化操作等黑箱操作方式使得模型的内部表示难以直观理解因此模型的解释性较差相比之下基于规则的方法和逻辑回归等传统机器学习方法具有较好的解释性虽然模型效果可能较差但仍得到广泛应用