语音识别是一种将人类语音转化为文本的技术。语音识别系统通常由多个步骤组成,包括信号采集、预处理、特征提取、模型训练、识别推断、后处理以及评估与优化。
1. 信号采集
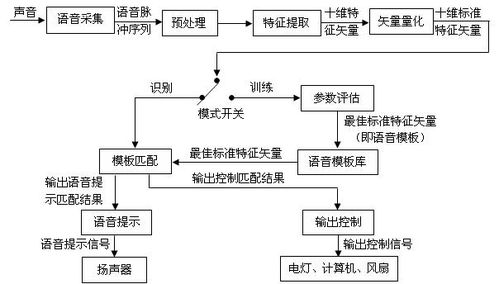
语音识别系统的第一步是信号采集。在这一步中,系统使用麦克风等设备捕获语音信号。这些信号然后被转换为数字格式,以便在计算机上进行处理。
2. 预处理
预处理是语音识别系统中的另一个重要步骤。在这个步骤中,系统对采集的信号进行滤波、标准化和归一化等操作,以消除噪声和不同说话人的差异,并使信号具有可比性。
3. 特征提取
在特征提取阶段,系统将语音信号转化为一组特征,这些特征可以反映语音信号的特性,例如音调、音色和音节等。这些特征被用于后续的模型训练和识别推断。
4. 模型训练
模型训练是语音识别系统中的关键步骤之一。在这个步骤中,系统使用大量的训练数据来训练模型,以识别不同的语音信号。训练的目标是使模型能够准确地识别语音信号,并将其转换为正确的文本。
5. 识别推断
在识别推断阶段,系统使用训练好的模型来处理输入的语音信号。它将语音信号转换为文本形式,并输出结果。
6. 后处理
后处理是对识别结果进行修正和整理的过程。这包括纠正错别字、语法检查以及将结果整理为可读的格式等。后处理可以提高识别结果的准确性和可读性。
7. 评估与优化
评估与优化是语音识别系统中的最后一步。在这个步骤中,系统对模型的性能进行评估,以确定模型的准确性和可靠性。根据评估结果,系统可以进行优化,以提高模型的性能和识别准确率。这可以通过改进模型结构、增加训练数据或者优化模型参数等方式实现。
语音识别技术是一种将人类语音转化为文本的重要技术。通过了解语音识别系统的基本过程,我们可以更好地理解这种技术的运作方式,并为进一步的研究和应用提供参考。