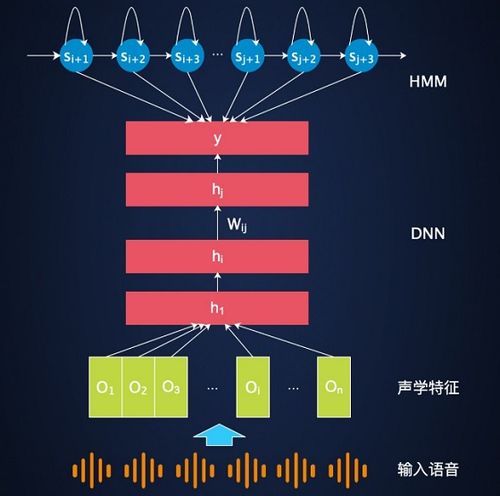
1. 引言
随着科技的不断发展,语音识别技术已经成为了人机交互的重要手段之一。传统的语音识别方法主要基于规则和模式匹配,随着数据量的不断增加和交互方式的多样化,传统的方法已经无法满足现代语音识别的需求。深度学习技术的兴起为语音识别领域带来了新的突破。本文将介绍深度学习在语音识别中的应用,包括预处理、模型训练与优化、模型评估与性能改进等方面。
2. 深度学习概述
深度学习是机器学习领域的一个分支,它基于人工神经网络,通过模拟人脑神经元的连接方式,构建一个大规模的神经网络。深度学习技术可以从数据中自动提取有用的特征,从而避免了手工设计特征的繁琐过程,同时也能够处理高维度的数据。在语音识别领域,深度学习技术可以用于语音信号的转换、特征提取和分类等方面。
3. 语音识别的重要性
语音识别是实现人机交互的重要手段之一,它可以让机器像人一样听懂人类语言,从而实现智能化的应用。语音识别技术在移动设备、智能家居、自动驾驶等领域都有广泛的应用,同时也为智能客服、情感分析、语音翻译等提供了可能。随着人工智能技术的不断发展,语音识别技术也将迎来更加广阔的发展空间。
4. 深度学习在语音识别中的应用
深度学习在语音识别中的应用主要体现在以下几个方面:
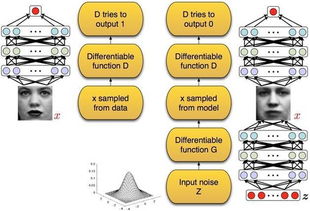
4.1 语音转换:深度学习技术可以用于语音信号的转换,例如将语音转换为文字、文字转换为语音等。其中,最常用的技术包括循环神经网络(R)和长短时记忆网络(LSTM)。
4.2 特征提取:深度学习技术可以从语音信号中自动提取有用的特征,避免了手工设计特征的繁琐过程。常用的技术包括卷积神经网络(C)和自动编码器(AE)。
4.3 分类和识别:深度学习技术可以用于语音信号的分类和识别,例如语音识别、情感分析等。常用的技术包括支持向量机(SVM)、决策树(DT)和神经网络等。
5. 语音数据的预处理
在深度学习应用于语音识别过程中,需要对原始音频数据进行一系列预处理操作,包括:预加重、分帧、加窗、MFCC特征提取等步骤。这些步骤旨在将连续的音频信号转化为适合神经网络处理的离散型特征表示。
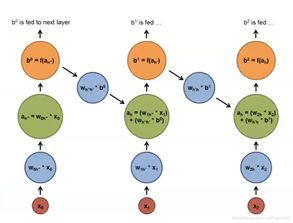
6. 深度学习模型的训练和优化
在预处理之后,我们需要对模型进行训练和优化。这个过程中,通常会使用大量的标注数据集进行监督学习。常见的模型包括全连接层(D)、循环神经网络(R)、长短期记忆网络(LSTM)、卷积神经网络(C)等。通过调整模型参数,比如学习率、批次大小、隐藏层节点数等,可以达到优化模型性能的目的。
7. 模型评估与性能改进
为了准确评估模型的性能,我们需要构建测试数据集,并采用各种评估指标,如准确率、召回率、F1值等。还可以通过可视化工具进行模型调试,以及使用早停(early soppig)和正则化(regularizaio)等技术防止过拟合。针对模型性能的不足之处,可以尝试采用更复杂的模型结构、使用更多的数据或者进行集成学习等方法进行改进。
8. 未来发展趋势和挑战
随着深度学习技术的不断发展和计算能力的提升,未来的语音识别系统有望实现更高的准确率和更低的延迟。同时,随着可解释AI的发展,我们也将更好地理解模型做出决策的原因。仍然存在许多挑战,如处理复杂环境和多语种问题、保护用户隐私等。我们需要在不断探索中寻求解决方案。