随着人工智能技术的不断发展,语音识别技术作为人机交互的重要手段之一,得到了广泛应用。而深度神经网络作为当前的机器学习算法之一,也被广泛应用于语音识别领域。本文将介绍语音识别深度神经网络的基本原理、网络架构与组成、数据预处理与准备、模型训练与优化、模型评估与比较、应用场景与实例以及未来展望与挑战。
2. 语音识别深度神经网络概述
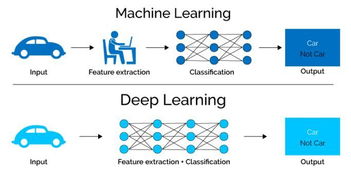
语音识别是一种将人类语音转化为文本的技术。深度神经网络是一种模拟人脑神经元网络结构的计算模型,由多个层次的神经元组成,能够自动学习和提取数据的特征。在语音识别领域,深度神经网络可以用来识别语音中的单词、短语、句子等,并且能够处理各种语言、口音和噪音情况。
3. 网络架构与组成
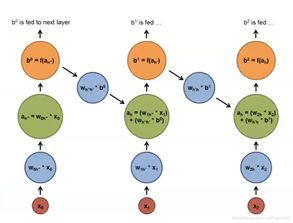
语音识别深度神经网络通常由多个层次的神经元组成,包括输入层、卷积层、循环层和输出层等。输入层负责接收音频信号,卷积层负责提取音频特征,循环层负责记忆和预测音频序列的特征,输出层负责输出识别结果。其中,卷积层和循环层是网络的核心部分,它们能够自动学习和提取音频信号的特征。
4. 数据预处理与准备
在训练深度神经网络之前,需要对语音数据进行预处理和准备。通常需要进行以下步骤:
预处理:将音频信号转化为数字信号,并进行切分和标准化等操作;
特征提取:提取音频信号的特征,如短时傅里叶变换(STFT)等;
标注:对音频信号进行标注,如转录文本等。
5. 模型训练与优化
在准备好数据之后,需要对深度神经网络进行训练和优化。通常需要进行以下步骤:
随机初始化网络参数;
将数据输入到网络中进行前向传播;
计算损失函数;
进行反向传播并更新网络参数;
重复以上步骤直到达到预设的迭代次数或准确率要求。
在训练过程中,还需要注意以下几点:
选择合适的激活函数和损失函数;
选择合适的优化器和学习率;
进行正则化操作以防止过拟合;
进行早停操作以防止训练时间过长。
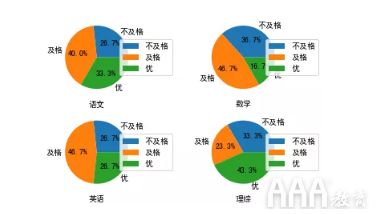
6. 模型评估与比较
在训练好深度神经网络之后,需要对模型进行评估和比较。通常会采用以下指标:
准确率:评估模型正确识别的样本数占总样本数的比例;
召回率:评估模型能够找出多少正确的样本;
F1值:准确率和召回率的调和平均数;
鲁棒性:评估模型对于不同口音、语速和环境噪音的适应能力。
同时,还需要与其他语音识别技术进行比较,如传统的机器学习方法、其他深度学习算法等,以评估模型的优劣。
7. 应用场景与实例
语音识别深度神经网络可以应用于各种场景,如智能客服、智能家居、车载语音助手、手机应用等。下面以智能客服为例进行说明:
智能客服可以帮助企业提高客户满意度和服务效率。通过语音识别深度神经网络技术,客户可以通过语音输入问题,智能客服可以自动回答问题并进行情感分析,以判断客户是否满意。同时,智能客服还可以自动记录客户反馈和建议,帮助企业改进产品和服务。
8. 未来展望与挑战
虽然语音识别深度神经网络已经取得了很大的进展,但是仍然存在一些挑战和问题需要解决。如:
提高识别准确率和鲁棒性:目前的语音识别技术还不能完全解决各种场景下的语音识别问题,需要进一步提高技术的鲁棒性和准确性;
保护用户隐私:语音识别需要采集用户的语音数据,如何保护用户隐私是一个需要解决的问题;
与其他技术的融合:语音识别技术可以与其他人工智能技术融合,如自然语言处理、计算机视觉等,以实现更加智能的人机交互。