====================
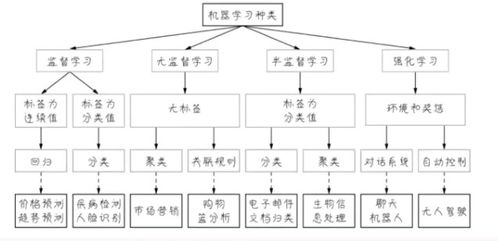
1. 监督式学习-------
### 1.1 定义与原理
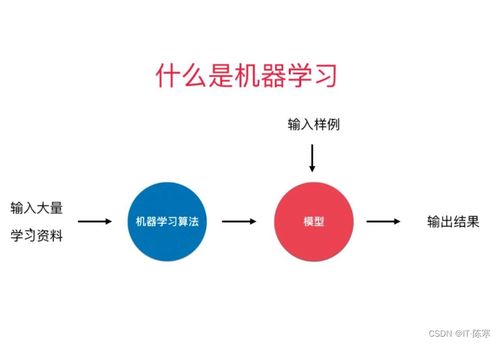
监督式学习是一种机器学习方法,其基本原理是通过对输入数据和已知输出数据(即标签)进行比较,以找出能够最小化预测误差的模型。在监督式学习中,每个输入样本都包含输入特征和相应的标签,训练目标是学习一个从输入特征到标签的映射。
### 1.2 算法与模型
监督式学习的主要算法包括线性回归、逻辑回归、支持向量机(SVM)、决策树等。这些算法在训练过程中使用已知的标签来优化模型的预测性能。经过训练后,这些模型可以独立地对新的、未标记的数据进行预测。
### 1.3 优缺点
优点:由于监督式学习使用有标签数据进行训练,因此它能够为预测提供较为精确的结果。当标签数据充足且质量较高时,监督式学习的效果通常较好。 缺点:监督式学习的一个主要限制是需要大量的有标签数据。有些情况下可能难以获取准确的标签,例如在某些应用中获取真实标签的成本很高或者某些数据点是噪声数据。
2. 无监督学习-------
###
2.1 定义与原理
无监督学习是一种机器学习方法,其基本原理是利用输入数据中包含的结构信息进行预测。在无监督学习中,输入数据并未包含标签信息,而是通过聚类、降维或异常检测等技术来发掘数据的内在结构。
###
2.2 算法与模型
无监督学习的主要算法包括K-均值聚类、层次聚类、主成分分析(PCA)等。这些算法通过分析输入数据的内在关系和结构来发掘数据的潜在模式。与监督式学习不同,无监督学习不依赖有标签数据进行训练,而是利用输入数据的内在结构进行预测。
###
2.3 优缺点
优点:无监督学习的一个主要优点是不需要大量的有标签数据。它能够从输入数据中自动发掘结构信息,因此对于那些标签数据难以获取或质量不高的应用场景来说,无监督学习具有很大的潜力。无监督学习还可以用于异常检测和异常值的识别。 缺点:无监督学习的一个主要限制是其预测结果的准确性通常不如监督式学习。这是因为它无法直接利用已知的标签信息来进行优化。无监督学习对于某些应用场景可能不适用,例如在那些需要明确类别信息的应用中。
总结--
监督式学习和无监督学习在不同的情况下各有优势。对于需要精确预测结果且标签数据充足的应用场景,监督式学习通常是更好的选择。而对于那些标签数据难以获取或质量不高的应用场景,无监督学习则可能更为适用。在实际应用中,应根据具体需求和数据特点来选择合适的机器学习方法。