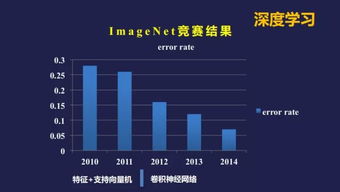
====================
监督式学习与无监督学习是机器学习的两种主要方法。它们在定义、示例、方法和应用场景上有所不同,但都为解决预测和分类问题提供了强大的工具。本文将详细介绍这两种学习范式,并比较它们的区别、应用场景以及常用的算法。
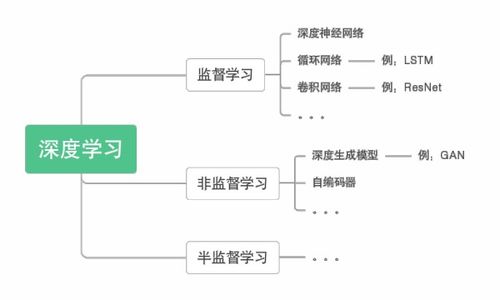
1. 监督式学习--------
### 定义
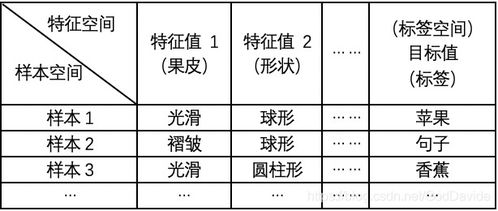
监督式学习是一种通过已知输入和输出来训练模型的方法。在训练过程中,模型学习从输入到输出的映射关系,以便在未知数据上进行预测。
### 示例
假设我们有一个带有标签的数据集,其中包含输入特征(如年龄、收入)和对应的输出标签(如信用评分)。监督式学习算法会学习输入特征与输出标签之间的关系,从而在新的数据上预测未知的标签值。
### 方法
监督式学习的主要方法包括线性回归、支持向量机(SVM)、逻辑回归等。这些方法在金融、医疗、自然语言处理等领域有着广泛的应用。
2. 无监督学习--------
### 定义
无监督学习是一种在没有标签的情况下,通过分析数据间的关系或聚类来训练模型的方法。在训练过程中,模型学习数据的内在结构和关系,以便在新的数据上进行预测或聚类。
### 示例
假设我们有一个包含多个特征的数据集,但并未标注任何标签。无监督学习算法可以发现数据中的模式和结构,例如通过聚类分析将数据分成几个组,或者通过降维分析将高维数据转化为低维数据。
### 方法
无监督学习的主要方法包括K-均值聚类、层次聚类、主成分分析(PCA)等。这些方法在市场细分、推荐系统、异常检测等领域有着广泛的应用。
3. 比较监督式学习和无监督学习------------------
### 区别
监督式学习依赖于已知的输入和输出数据来训练模型,而无需对数据进行内在结构和关系进行分析;而无监督学习则完全依赖于输入数据本身来训练模型,没有预设的输出标签。
### 应用场景
监督式学习适用于具有明确标签的数据集,例如信用卡欺诈检测、疾病诊断等;而无监督学习适用于没有明确标签的数据集,例如市场细分、用户行为分析等。
4. 监督式学习算法------------
### 线性回归
线性回归是一种用于回归分析的监督式学习算法。它通过拟合一个线性模型来预测连续的目标变量。线性回归在金融预测、自然语言处理等领域有着广泛的应用。
### 支持向量机
支持向量机(SVM)是一种用于分类问题的监督式学习算法。它通过将数据映射到高维空间中,并找到一个间隔最大的超平面来分类数据。SVM在文本分类、图像识别等领域有着广泛的应用。
### 逻辑回归
逻辑回归是一种用于二元分类问题的监督式学习算法。它通过使用逻辑函数将线性回归的结果转化为概率值,以便进行分类。逻辑回归在信用评分、疾病诊断等领域有着广泛的应用。
5. 无监督学习算法------------
### K-均值聚类
K-均值聚类是一种无监督学习的常用算法。它通过将数据划分为K个不重叠的子集(即聚类),使得同一聚类内的数据相互之间更接近(或相似)。K-均值聚类在市场细分、客户分群等领域有着广泛的应用。
### 层次聚类
层次聚类是一种无监督学习的算法,它通过将数据点或类别按照距离进行层次分解,从而形成一个树状的聚类结构。层次聚类在探索性数据分析、图像分割等领域有着广泛的应用。
### 主成分分析
主成分分析(PCA)是一种常用的无监督学习算法,它通过将高维数据转化为低维数据,并保留最重要的特征,以便进行数据分析和可视化。PCA在异常检测、图像压缩等领域有着广泛的应用。