================
监督式学习与无监督学习是机器学习的两种主要方法。这两种方法在定义、示例、方法和应用场景等方面存在差异,但都在人工智能领域中发挥着重要作用。
1. 监督式学习-------
### 定义
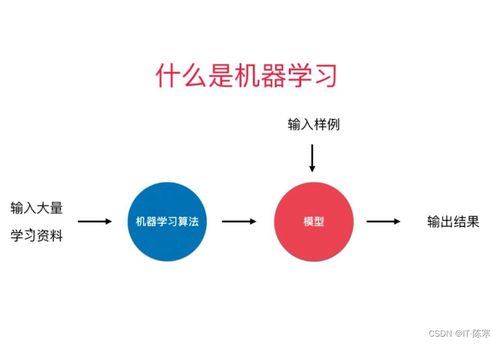
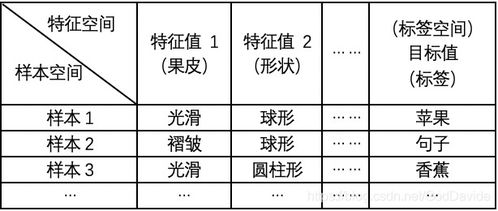
监督式学习是一种机器学习方法,它依赖于标记好的训练数据,这些数据包含了输入和期望的输出。通过训练,模型学会将输入映射到期望的输出。
### 例子
假设我们有一个数据集,其中包含顾客信用卡交易的数据,并且我们知道哪些交易是欺诈性的。监督式学习可以用来训练一个模型,使其能够识别新的交易是否可能是欺诈性的。
### 方法
监督式学习的主要方法包括回归分析、逻辑回归、决策树、支持向量机(SVM)等。这些方法都试图最小化模型预测结果与实际结果之间的误差。
2. 无监督学习-------
### 定义
无监督学习是一种机器学习方法,它不需要标记好的训练数据。模型从输入数据中学习其内在结构和关系。
### 例子
无监督学习的一个例子是在聚类分析中,模型不需要知道任何关于数据的标签信息,而是通过算法将相似的数据点聚集在一起。
### 方法
无监督学习的主要方法包括聚类分析、降维、关联规则学习等。这些方法试图从数据中提取有用的信息,如找出相似的对象或识别出数据的潜在结构。
3. 比较----
### 区别
监督式学习依赖于标记好的训练数据,试图最小化预测结果与实际结果之间的误差;而无监督学习则不需要标记数据,试图从数据中找出结构或关系。
### 应用场景
监督式学习通常用于需要预测结果的任务,如分类或回归问题;而无监督学习通常用于找出数据的内在结构或关系,如聚类分析或降维。
4. 结论-----
监督式学习和无监督学习都是机器学习的重要分支,各自有其优势和应用场景。在实践中,它们经常被结合使用,以解决复杂的问题。随着人工智能技术的不断发展,这两种方法的应用和优化也将持续进行。未来,随着大数据和深度学习的发展,监督式学习和无监督学习将在更多领域得到广泛应用,如医疗诊断、自然语言处理、推荐系统等。同时,随着算法和计算能力的提升,我们期待看到更多创新的机器学习方法出现,以更好地解决复杂的问题。