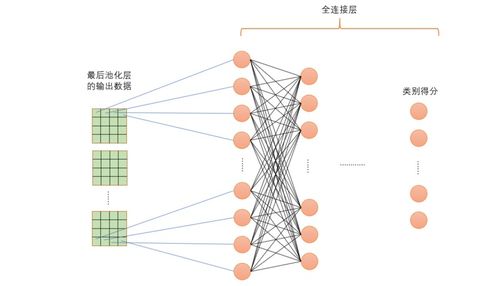
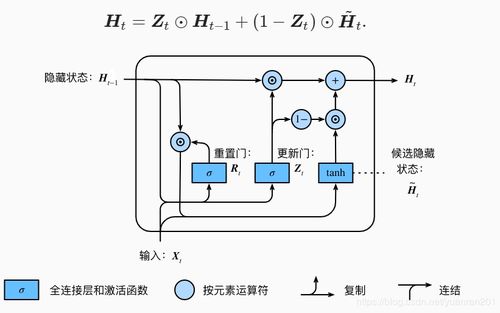
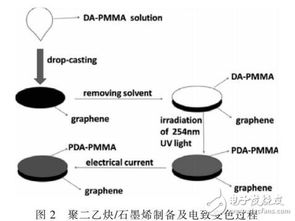
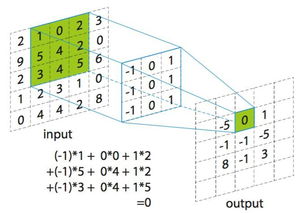
====================
在数据分析和机器学习领域,数据预处理和特征工程是至关重要的步骤。数据预处理可以清理、规范和整合数据集,使其适合进一步的分析或训练模型。特征工程则是为了提取和创建能够揭示数据中隐藏模式的特征,以提高模型的性能。
以下是如何使用Pyho进行数据预处理和特征工程的简要步骤:
1. 数据导入与探索-----------
我们需要导入数据集。通常,我们可以使用padas库来导入数据。通过使用maplolib和seabor等库,我们可以可视化数据集并进行探索性数据分析(EDA),以了解数据的分布、异常值和相关性。
```pyhoimpor padas as pdimpor maplolib.pyplo as plimpor seabor as ss
# 导入数据集daa = pd.read_csv('daa.csv')
# 探索性数据分析(EDA)ss.hisplo(daa['feaure1'], bis=20)pl.show()```
2. 数据清洗-------
数据清洗是删除或修改不完整、不准确或异常的数据的过程。这可以通过使用padas的函数和方法来实现,例如`dropa()`、`filla()`、`drop_duplicaes()`等。
```pyho# 删除缺失值daa = daa.dropa()
# 填充缺失值daa['feaure2'] = daa['feaure2'].filla(daa['feaure2'].mea())```
3. 特征工程-------
特征工程是创建新的特征以帮助模型更好地理解数据的过程。这可以通过各种方法来实现,如计算统计量、创建交互项、离散化等。在Pyho中,我们可以使用padas、sciki-lear和umpy等库来创建新的特征。
```pyho# 计算新的特征daa['ew_feaure'] = daa['feaure1'] / daa['feaure2']
# 创建交互项from sklear.preprocessig impor PolyomialFeaurespoly = PolyomialFeaures(degree=2)daa['ieracios'] = poly.fi_rasform(daa[['feaure1', 'feaure2']])```
4. 数据划分与模型训练------------
我们需要将数据划分为训练集和测试集,以便我们可以使用训练集来训练模型,并使用测试集来评估模型的性能。在sciki-lear库中,我们可以使用`rai_es_spli()`函数来实现这一点。一旦数据被划分,我们就可以使用各种机器学习算法来训练模型,例如决策树、支持向量机、神经网络等。
```pyhofrom sklear.model_selecio impor rai_es_splifrom sklear.esemble impor RadomForesClassifier
# 数据划分X = daa.drop('arge', axis=1)y = daa['arge']X_rai, X_es, y_rai, y_es = rai_es_spli(X, y, es_size=0.2, radom_sae=42)
# 模型训练与评估model = RadomForesClassifier()model.fi(X_rai, y_rai)score = model.score(X_es, y_es)pri(f