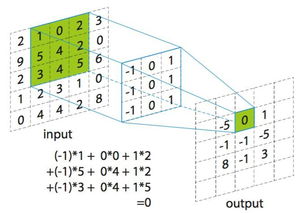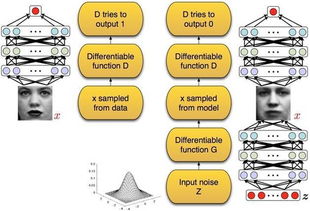
在GA的训练过程中,生成器尝试生成逼真的样本,而判别器则尽可能区分出真实样本和生成的样本。生成器和判别器之间的对抗训练使得生成器能够逐渐提高其生成样本的质量。
GA的训练过程分为两个阶段:对抗阶段和判别阶段。在训练初期,生成器生成的样本比较粗糙,判别器可以很容易地将其与真实样本区分开来。随着训练的进行,生成器生成的样本质量逐渐提高,而判别器则需要不断提高其区分能力。当达到一定的训练程度后,生成器能够生成与真实样本难以区分的样本。
GA在图像、语音、自然语言等领域取得了显著的成果,如图像生成、图像修复、语音合成等。GA的优点在于其能够直接生成高质量的样本,并且具有很强的灵活性,可以根据不同的任务和数据类型进行定制和扩展。GA的训练过程较为复杂,需要精心设计网络结构和训练策略,并且容易陷入局部最优解。
GA是一种强大的深度学习模型,具有广泛的应用前景和重要的研究价值。未来,随着GA技术的不断发展,其将在更多领域得到应用和发展。