======================
引言--
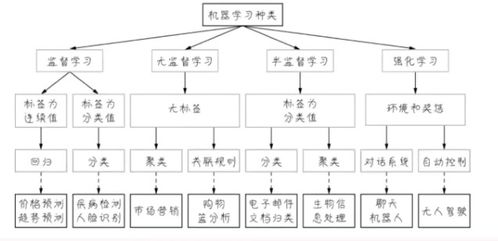
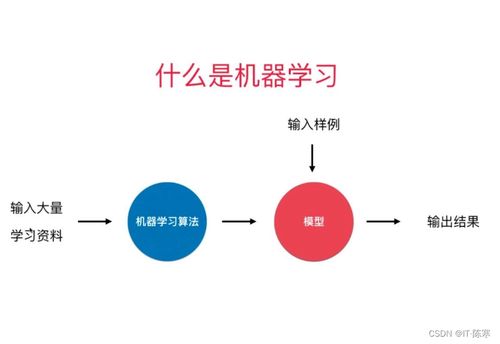
监督式学习和无监督学习是机器学习的两种主要方法。它们在定义、实例、方法以及应用场景等方面存在显著的差异。本文将详细介绍这两种学习方法,并通过比较来揭示它们的区别和应用场景。我们将讨论这两种方法未来的发展趋势。
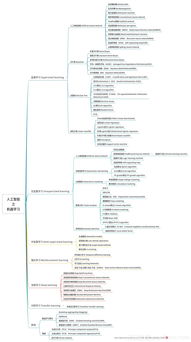
监督式学习----
### 定义
监督式学习是一种机器学习方法,它通过已知输入和输出来训练模型。在此过程中,模型学习从输入到输出的映射规则。
### 实例
以图像分类为例,监督式学习算法可以训练识别猫、狗等类别的模型。在这个过程中,每个图像都带有标签(猫或狗),作为模型的训练目标。
### 方法
监督式学习的主要方法包括回归分析、逻辑回归、支持向量机(SVM)、决策树等。这些方法都基于已知标签的数据来训练模型。
无监督学习------
### 定义
无监督学习是一种机器学习方法,它利用没有标签的数据来训练模型。在此过程中,模型学习数据的内在结构和关系。
### 实例
以聚类为例,无监督学习算法可以用来将用户分为不同的群体,例如根据用户的购买历史来进行市场细分。在这个过程中,用户的购买历史作为输入数据,而用户所属的群体是未知的,需要模型进行推断。
### 方法
无监督学习的主要方法包括聚类分析、关联规则挖掘、降维等。这些方法都基于数据本身的内在关系来训练模型。
比较--
### 区别
1. 输入数据:监督式学习需要带有标签的数据,而无监督学习则不需要。
2. 训练目标:监督式学习旨在学习从输入到输出的映射规则,而无监督学习则是为了发掘数据的内在结构和关系。
3. 应用场景:监督式学习广泛应用于图像分类、语音识别等领域,而无监督学习则更多应用于市场细分、推荐系统等领域。
4. 模型评估:由于无监督学习没有标签数据,因此其模型评估相对更为复杂。
### 应用场景
1. 监督式学习:图像识别(猫、狗分类)、语音识别(转录)、自然语言处理(情感分析)等。
2. 无监督学习:市场细分、推荐系统(协同过滤)、降维等。
结论--
监督式学习和无监督学习是机器学习的两种主要方法,它们各具特色,分别适用于不同的应用场景。随着数据量的增长和计算能力的提升,这两种方法在未来都有广阔的发展空间。特别是在无监督学习领域,随着数据挖掘和推荐系统等需求的增长,其应用将会更加广泛。同时,随着深度学习和强化学习等技术的不断发展,这两种学习方法也将得到进一步的改进和完善。