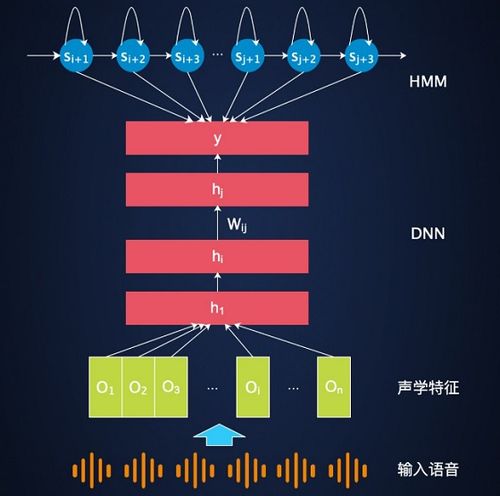
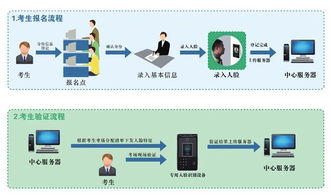
1. 引言
GA是一种生成模型,它通过让生成器与判别器进行对抗,从而生成高质量的假数据。与传统的生成模型不同,GA不需要显式地最大化数据分布,而是通过最小化对抗性损失函数来学习数据分布。GA在图像、语音、自然语言等领域取得了很大的成功,它可以用来生成新的图像、音频和文本等。
2. 生成对抗网络概述
GA由一个生成器和一个判别器组成。生成器的任务是生成假数据,而判别器的任务是区分真实数据和假数据。在训练过程中,生成器和判别器会进行对抗性训练,直到生成器能够生成足够好的假数据来欺骗判别器。
3. GA的基本结构
生成器的结构通常包括一个编码器和一个解码器。编码器将输入数据编码成隐含表示,解码器将隐含表示解码成输出数据。判别器的结构类似于一个普通的分类器,它可以将输入数据分类为真实数据或假数据。
4. GA的训练过程
GA的训练过程包括两个阶段:判别器训练和生成器训练。在判别器训练阶段,使用真实数据和生成器生成的假数据进行训练,使得判别器能够尽可能地区分真实数据和假数据。在生成器训练阶段,使用梯度下降等方法更新生成器的参数,使得生成器能够生成足够好的假数据来欺骗判别器。
5. GA的应用场景
GA的应用场景非常广泛,包括图像、语音、自然语言等领域。例如,在图像领域,GA可以用来生成新的图像、图像超分辨率等;在语音领域,GA可以用来生成新的音频数据等;在自然语言领域,GA可以用来生成新的文本数据等。
6. GA的优缺点
GA的优点包括:可以生成高质量的假数据、可以学习复杂的分布、可以进行无监督学习等。但是,GA也存在一些缺点,例如:训练不稳定、难以调试、计算量大等。
7. GA的未来发展趋势
随着深度学习技术的不断发展,GA也将继续发展。未来,GA可能会在以下几个方面有所改进:提高训练稳定性、改进训练方法、降低计算量等。同时,随着应用场景的不断扩展,GA也将在更多的领域得到应用。