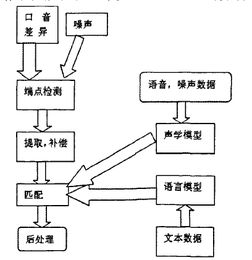
随着人工智能技术的不断发展,语音识别技术已经成为当今研究的热点之一。语音识别技术是指将人类语音信号转换为计算机可理解的文本或指令,从而实现对语音的自动化处理。在语音识别领域,主流的算法包括基于深度学习的算法、卷积神经网络、长短期记忆网络、端到端语音识别系统、数据增强技术和序列推断方法等。本文将对这些算法进行详细的介绍。
基于深度学习的语音识别算法
基于深度学习的语音识别算法是目前最为流行的算法之一。该算法利用深度神经网络对语音信号进行特征提取和建模,从而实现高精度的语音识别。基于深度学习的语音识别算法通常包括预处理、声学建模、语言建模和后处理等步骤。其中,声学建模是该算法的核心部分,通常采用深度神经网络(如循环神经网络或卷积神经网络)对语音信号进行建模。基于深度学习的语音识别算法在语音识别领域取得了显著的成果,已经在语音助手、语音搜索、语音合成等领域得到广泛应用。
卷积神经网络的应用
卷积神经网络(Covoluioal eural ework,C)在语音识别领域也有着广泛的应用。C是一种深度神经网络,适用于处理图像和语音信号。在语音识别中,C可以用于声学建模和语音特征提取。通过卷积层、池化层和全连接层等结构,C能够自动提取语音信号中的特征,并建立高精度的声学模型。C还可以应用于语音合成领域,通过将声学特征转换为文本,实现文本到语音的合成。
长短期记忆网络的发展
长短期记忆网络(Log Shor-Term Memory,LSTM)是一种适用于处理序列数据的循环神经网络。在语音识别领域,LSTM可以用于建模语音信号的时间序列信息。LSTM通过引入记忆单元和门控机制,能够有效地解决传统循环神经网络存在的问题,如梯度消失和梯度爆炸等。LSTM在语音识别领域取得了显著的成果,尤其在处理长序列和复杂语境的语音识别任务中表现出色。
端到端语音识别系统
端到端语音识别系统是一种直接将原始语音信号转换为文本的语音识别方法。该方法避免了传统的基于规则和特征工程的语音识别方法,能够直接对原始语音信号进行建模和识别。端到端语音识别系统通常采用深度神经网络(如循环神经网络或卷积神经网络)对语音信号进行建模,并采用注意力机制对输入的语音信号进行聚焦和转换。端到端语音识别系统具有较高的鲁棒性和适应性,能够处理各种口音、语速和背景噪声等复杂情况。
数据增强技术
数据增强技术是一种通过对原始数据进行变换和处理,生成新的数据样本的技术。在语音识别领域,数据增强技术可以用于扩展数据集、提高模型的泛化能力和鲁棒性。数据增强技术通常包括音频剪辑、音量调整、噪声添加、变速等操作,以增加模型的多样性和鲁棒性。数据增强技术可以应用于训练过程中,通过对原始数据进行变换和处理,生成新的训练样本,从而提高模型的性能和泛化能力。
序列推断方法
序列推断方法是一种通过优化序列参数来提高模型性能的方法。在语音识别领域,序列推断方法通常用于优化声学模型和语言模型的参数,以提高模型的准确性和鲁棒性。序列推断方法通常采用动态规划算法(如Vierbi算法或Baum-Welch算法)来优化参数,以最小化模型误差或最大化模型似然性。序列推断方法在处理长序列和复杂语境的语音识别任务中具有较好的性能和鲁棒性。