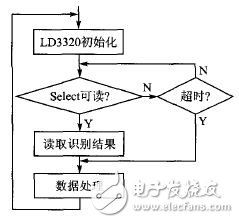
生成对抗网络(GA)是一种深度学习模型,由两个神经网络组成:生成器网络和判别器网络。它通过竞争性的训练过程,使得生成器网络能够生成足以以假乱真的数据,同时判别器网络能够准确地区分真实数据和生成的数据。
1. GA的基本结构
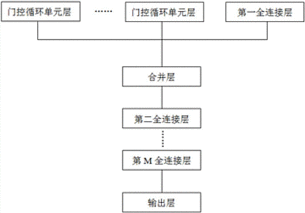
GA由生成器和判别器两个神经网络组成。生成器负责生成新的数据样本,而判别器则负责判断输入的数据样本是真实的还是由生成器生成的。在结构上,生成器网络和判别器网络都包含一个或多个隐藏层和一个输出层。
2. 生成器网络
生成器网络负责生成新的数据样本。它接受一个随机噪声向量作为输入,并经过一系列的非线性变换和转换,最终生成一个新的数据样本。生成器网络的输出结果应尽可能接近真实数据分布。
3. 判别器网络
判别器网络负责判断输入的数据样本是真实的还是由生成器生成的。它接受一个数据样本和一个噪声向量作为输入,然后输出一个判断结果,表示输入样本是由真实数据还是生成器生成的数据。判别器网络的目的是尽可能准确地区分真实数据和生成的数据。
4. 训练过程
GA的训练过程是一个迭代的过程。在每一次迭代中,生成器会生成一个新的数据样本,然后将其输入到判别器中。判别器会根据其训练数据和噪声向量判断该样本是真实的还是生成的。然后,根据判别器的判断结果,更新生成器和判别器的权重参数,以使得生成器能够生成更真实的数据样本,而判别器能够更准确地区分真实数据和生成的数据。
5. GA的应用场景
GA在许多领域都有广泛的应用,例如图像生成、语音合成、自然语言处理等。GA能够生成高质量的图像和音频数据,以及实现文本到图像的转换等任务。GA还可以用于数据隐私保护、异常检测和强化学习等领域。
6. GA的优缺点
GA的优点在于其能够生成高质量的数据样本,并且具有强大的表示能力和灵活性。GA还能够解决一些传统机器学习方法难以处理的问题,例如图像和语音识别等任务。GA也存在一些缺点,例如训练过程不稳定、难以调试和优化等问题。GA还可能存在模式崩溃的问题,即生成器生成的数据样本不够多样化或重复性过高。
7. GA的未来发展方向
随着深度学习技术的不断发展,GA在未来还将有更多的应用和发展方向。例如,可以使用更复杂的网络结构来提高GA的性能和质量;可以使用不同的优化算法来加速GA的训练过程;还可以将GA与其他深度学习技术相结合,以实现更复杂的任务和应用。随着数据隐私保护越来越受到关注,GA在数据隐私保护方面也将有更多的应用和发展。